Ufficio Centrale per lo sviluppo e la gestione del Sistema Informativo
 |
MetoDoc v1.0 |
|
MetoDoc v1.0 |
Líimplementazione di un sistema informatico è la fase conclusiva della produzione del software gestionale.
Il presente capitolo si propone di fornire delle linee guida per la fase di implementazione di software industriale di tipo gestionale.
A tal fine traccia una panoramica del contesto (architetture, DBMS, linguaggi visuali) e propone indicazioni per sfruttare al meglio gli strumenti a disposizione, fornendo anche esempi di utilizzo.
La fase di Implementazione riceve in input, dalla Progettazione, il Documento di Progetto, il DFD, lo Schema Logico dei Dati e produce in output la Base di Dati, il Codice Testato e il Manuale Utente dellíintero progetto come schematizzato in Figura 6.4.1.
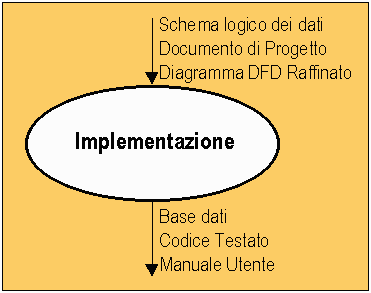
Figura 6.4.1 ñ Il prodotto della fase di Implementazione.
Architettura distribuita e DBMS relazionale sono il punto di riferimento del quadro metodologico proposto.
Per quanto riguarda la prima si espongono sotto i concetti principali per un approfondimento dei quali si rimanda al volume di Atzeni. Per la seconda si rimanda in toto al medesimo volume.
La progettazione fisica di una Base di Dati, essendo fortemente legata al prodotto utilizzato, difficilmente può essere guidata da suggerimenti validi in ogni contesto.
La creazione di indici in ogni campo di join ed in ogni campo utilizzato per ordinamenti sembra comunque essere buona norma per ottimizzare i tempi di risposta della base di dati.
6.4.1.1 Architettura Client-Server
Líarchitettura Client-Server si basa sulla distinzione di ruoli che possono giocare le diverse componenti di un sistema, intendendo per sistema una o più macchine tra loro in comunicazione (anche una sola macchina può comportarsi funzionalmente come se al suo interno una parte svolgesse il ruolo di Client ed uníaltra il ruolo di Server).
Una macchina Client ha un ruolo attivo: effettua poche richieste di servizi alla macchina Server; una macchina Server ha un ruolo reattivo: confeziona molte risposte per le varie macchine Client.
Un esempio classico di architettura Client-Server è costituito da un DB Server interrogato da un browser Client.
Líindividuazione di ruoli è funzionale anche alla distribuzione di responsabilità: líattività del Client è legata al implementatore dellíapplicazione mentre líattività del Server è legata allíamministratore della base di dati.
I ruoli, teoricamente interscambiabili, diventano in realtà fissi nel momento in cui si dimensionano le macchine: un Client necessita di un unico processore, di sufficiente memoria volatile (finalizzata al supporto dellíinterfaccia grafica, alla formulazione delle domande al Server ed alla elaborazione delle riposte dal Server) e sufficiente memoria di massa; un Server necessita di più processori, massima memoria volatile (finalizzata a minimizzare le operazioni di lettura e scrittura su memoria di massa) e massima memoria di massa.
6.4.1.2 Base di dati distribuita
La base di dati distribuita risponde ad un'esigenza aziendale, per cui ogni dato viene gestito dove è prodotto; a fronte dellíevidente vantaggio della modularità e resistenza ai guasti di un sistema distribuito, si ha líinconveniente di dover spesso integrare sistemi eterogenei (dbms diversi) e geograficamente lontani (wan).
La situazione opposta (sistemi omogenei in lan) si verifica per lo più quando il sistema viene progettato ex-novo, senza vincoli organizzativi preesistenti.
Líintegrazione di sistemi può essere realizzata in due modi diversi: tramite la portabilità (líinterazione è affidata a linguaggi universali quali C e SQL) o líinteroperabilità (líinterazione è affidata a protocolli di traduzione quali ODBC e X-Open): la prima modalità è realizzata al momento della compilazione, la seconda al momento dellíesecuzione.
Tramite ODBC (Open Data Base Connectivity) líinteroperabilità è garantita da driver che mascherano differenze di DBMS, sistema operativo e rete; tramite X-OPEN DTP (Distribuited Transaction Processing) sono invece i DBMS che devono prevedere uníinterfaccia comune (XA).
Obiettivo della base di dati distribuita è comunque minimizzare l'interazione e le trasmissioni via rete, garantendo autonomia locale ai Server. Fra i fattori di costo di una interrogazione distribuita vi è infatti la quantità di dati trasmessa in rete.
La frammentazione della base di dati dipende dunque da esigenze organizzative oltre che di performance: un esempio di risposta alla prima esigenza è la frammentazione orizzontale di una tabella in cui ogni unità di uníazienda gestisce localmente le sole tuple che la riguardano (dipendenti di Roma, dipendenti di Milano, ecc.); un esempio di risposta alla seconda esigenza è la frammentazione verticale di una tabella in cui gli attributi acceduti più frequentemente vengono posti su una tabella separata (livello retributivo, anzianità di servizio, ecc.).
Una transazione è un insieme atomico di operazioni (display, insert, delete, update) per cui è accettabile che siano eseguite tutte o nessuna.
Un esempio di transazione è il trasferimento di denaro da un conto ad un altro.
Tale operazione si ottiene tramite due update: uno sul primo conto, che viene decrementato , e líaltro sul secondo, che viene incrementato.
Líeventuale fallimento dellíesecuzione del secondo update deve provocare líannullamento del primo update, per non lasciare la base di dati in una situazione non consistente.
Un sistema si dice transazionale se offre la possibilità di definire transazioni ed il suo carico applicativo si misura in tps (transazioni per secondo).
Definire una transazione significa incapsulare le operazioni che la compongono fra i due comandi Begin Of Transaction (BOT) ed End Of Transaction (EOT).
Le operazioni non hanno alcun effetto persistente sulla base di dati se non sono finalizzate dal comando Commit work (commit); identico risultato si ottiene se la transazione viene chiusa da un comando Roll Back Work (abort).
La necessità di introdurre nei record del file di log líidentificativo della transazione che effettua líaccesso al dato è funzionale allíisolamento che deve essere garantito ad ogni singola transazione rispetto alle altre che contemporaneamente richiedono líaccesso alle stesse informazioni.
La probabilità che più transazioni entrino in conflitto richiedendo contemporaneamente líaccesso allo stesso dato è direttamente proporzionale al numero di transazioni ed al numero di risorse cui accede mediamente una transazione ed inversamente proporzionale al numero di oggetti presenti sulla base di dati.
Tale probabilità aumenta in funzione della rilevanza (numero di relazioni con gli altri oggetti) di un oggetto allíinterno della base di dati.
La concorrenza viene risolta tramite meccanismi di serializzazione delle transazioni, ossia eseguendo le transazioni come se non fossero in concorrenza ma bensì in sequenza.
6.4.2 Tecniche di programmazione
Il contesto cui fa riferimento il quadro metodologico proposto è quello dei linguaggi visuali. L'utilizzo di essi porta naturalmente ad acquisire le tecniche di programmazione modulare, finalizzate alla riduzione della complessità dei problemi da risolvere oltre che al riutilizzo ed alla manutenzione dei programmi, grazie allíassociazione modulo-funzionalità.
Il riferimento bibliografico in tal senso è il capitolo di Santucci "Metodologie e tecniche di programmazione modulare" nel testo di Ercoli.
In fine vengono forniti in allegato, a titolo esemplificativo, un algoritmo di ricerca ed uno di ordinamento con i relativi diagrammi di flusso. Per una trattazione approfondita si rimanda al volume di Ausiello.
6.4.2.1 Programmazione modulare
Il metodo di programmazione modulare ha come obiettivo la riduzione della complessità dei problemi da risolvere. Per complessità intendiamo la difficoltà di comprendere e risolvere i problemi. Líidea che sta alla base della programmazione modulare è quella di ridurre la complessità di un problema suddividendolo in sottoproblemi. La programmazione modulare parte dal presupposto che, suddividendo correttamente un programma in moduli, anche considerando la complessità delle interrelazioni fra i moduli, la complessità globale risulta ridotta.
La modularizzazione di un programma solleva due questioni; la prima di carattere quantitativo (sulle dimensioni dei moduli) e la seconda di carattere qualitativo (sui criteri di suddivisione dei moduli).
Per quanto riguarda gli aspetti quantitativi al diminuire delle dimensioni diminuisce la complessità di un modulo, ma aumenta il numero dei moduli e quindi la complessità delle loro interrelazioni.
Sulla qualità del processo di suddivisione di un programma in moduli, si tratta di introdurre dei criteri che rendano minima la complessità dei moduli e delle loro interrelazioni. I criteri di suddivisione possono riassumersi in:
Un modulo consiste in un insieme di istruzioni, con un insieme di variabili locali, identificato da un nome, la cui esecuzione può essere richiamata attraverso tale nome. Nel modulo possiamo distinguere:
Líimportanza della distinzione di questi tre concetti consiste nel fatto che quando si descrive un singolo modulo si deve far sempre riferimento alla sua funzione e non alla sua logica o al suo contesto.
Per coesione di un modulo síintende la misura del legame che esiste fra le singole parti (op. elementari o istruzioni) di un modulo. E' possibile definire dei criteri secondo i quali le istruzioni sono aggregate. Questi criteri rappresentano livelli diversi di coesione e sono in ordine di coesione crescente:
Questi tre tipi di coesione sono criteri non desiderabili di aggregazione di funzioni o operazioni. Costituiscono invece criteri di aggregazione consigliati i tre tipi di coesione analizzati di seguito:
Líaccoppiamento è la misura delle interrelazioni che esistono fra i moduli di un programma. Líobiettivo della metodologia di programmazione modulare è quello di ridurre líaccoppiamento fra i moduli.
Esistono diversi tipi e livelli di accoppiamento, ma si definiscono i seguenti quattro tipi, elencati in ordine decrescente di accoppiamento;
6.4.2.2 Esempi di algoritmi
Gli algoritmi descritti in allegato, con la relativa pseudocodifica, hanno lo scopo, puramente esemplificativo, di mostrare come una soluzione possa essere efficacemente rappresentata tramite gli strumenti a disposizione.
Ma più ancora vogliono essere, in un contesto industriale, un caldo invito a non reinventare le soluzioni ma ad utilizzare quelle esistenti.
Si sottolinea che líobiettivo della singola funzione (il cosa deve fare) non è mai un problema della fase di implementazione, in quanto già in fase di progettazione le responsabilità sono state definite e scomposte, e gli obiettivi di ciascuna di esse sono stati individuati ancora precedentemente, in fase di analisi.
Líimplementatore dovrà dunque concentrarsi sul come risolvere un determinato problema integrando soluzioni già esistenti nei seguenti termini:
Durante líattività di implementazione líimplementatore ha a sua disposizione strumenti atti a rappresentare a diversi livelli di astrazione la funzionalità da implementare.
Per livello di astrazione si intende qui il livello di indipendenza dalla macchina che verrà utilizzata.
Ciascuno strumento può, a sua volta essere usato a diversi livelli di astrazione, intesa qui come dettaglio di rappresentazione, ma caratteristica comune a tutti gli strumenti e ad ogni livello di astrazione è líalto formalismo, nel senso che i costrutti realizzati con tali strumenti devono osservare regole rigorose.
Gli strumenti sono: Diagrammi a blocchi, Pseudocodifica, Linguaggio di programmazione.
Essendo i tre strumenti utilizzati per lo più in cascata, devono necessariamente essere allineati, ossia ogni variazione apportata ad una rappresentazione prodotta con uno strumento di livello più alto si deve riflettere sulle rappresentazioni prodotte con gli altri strumenti di livello più basso, mentre non necessariamente accade il contrario (una lieve modifica al codice potrebbe riflettersi solo parzialmente sulla pseudocodifica e non riflettersi affatto sul diagramma a blocchi).
I diagrammi a blocchi uniscono la potenza espressiva della rappresentazione grafica al rigore formale derivato dal numero finito di simboli utilizzabili ed al significato standard ad essi attribuito.
Ogni algoritmo di una certa complessità deve essere documentato con un diagramma a blocchi, eventualmente esploso su più livelli di astrazione affinchè la modularizzazione funzionale possa già affiorare in questa fase alta dellíimplementazione.
Al di là di ogni documentazione in linguaggio naturale inserita direttamente del codice, la cui espressività si riduce col passare del tempo e con líevolversi dei linguaggi di programmazione, il diagramma a blocchi resta líunica chiave di accesso da cui ripartire quando non cíè più memoria della logica di una funzionalità.
Nel caso poi di rifacimento completo della funzionalità in un altro linguaggio di programmazione, è líunico strumento che permette di non ripartire dallíanalisi del codice per desumere come líobiettivo della funzione debba essere conseguito.
La pseudo codifica si pone ad un livello intermedio di astrazione: non usa ancora le parole del linguaggio di programmazione ma ne utilizza la sintassi.
Eí un passo spesso trascurato nellíimplementazione del software, ma i suoi benefici sono evidenti se si pensa alla distribuzione di compiti che consente: un implementatore esperto che non conosce un particolare linguaggio di programmazione può comunque scrivere un programma in pseudocodifica e passarlo a chi ha le competenze necessarie per la traduzione.
In questo contesto, diversi livelli di astrazione possono essere rappresentati raggruppando in routine gruppi di istruzioni, secondo le indicazioni della programmazione modulare.
6.4.3.3 Linguaggio di programmazione
Il linguaggio di programmazione è la parte fortemente dinamica del processo di implementazione.
La maturazione delle tecnologie ha svincolato sempre più líimplementatore dalla gestione del byte, consentendo da un lato una costante riduzione dei tempi di sviluppo ma dallíaltro imponendo ritmi serrati nellíapprendimento del nuovo e costringendo a riconversioni del software.
I linguaggi visuali ed orientati agli oggetti sono lo stato dellíarte dei linguaggi di programmazione e la loro affermazione è dovuta principalmente allíalto livello di riusabilità dei componenti.
Non è compito della metodologia suggerire un linguaggio piuttosto di un altro, anche perché sempre più spesso non è líorganizzazione a scegliere il linguaggio ma è il mercato ad imporlo.
Rivolgendosi, questa metodologia, a chi sviluppa software industriale di tipo gestionale, líindicazione è quella di non cercare soluzioni nelle nicchie di mercato in quanto il reperimento e le formazione di specialisti risulta poi onerosa.
Durante líutilizzazione del linguaggio scelto devono essere tenute in debita considerazione le seguenti buone norme di stesura e documentazione del codice.
Premettere una testata a qualunque funzione che riporti i seguenti dati:
Utilizzare qualunque strumento grafico per facilitare la lettura del codice:
Commentare almeno i passaggi meno evidenti secondo le seguenti indicazioni:
Fare in modo che il codice abbia le seguenti caratteristiche:
Il Manuale Utente è parte integrante del prodotto software, attinge struttura e contenuti dal Documento di Analisi ed è la guida per ogni ipotetico utente.
Sarebbe auspicabile che ogni maschera, ed ogni campo allíinterno di essa, avesse il suo help on line.
In tal caso il manuale cartaceo altro non dovrebbe essere che la stampa dellíhelp on line integrata dai necessari collegamenti fra maschere e dalla guida alle operazioni da compiere.
Nel Manuale, líutente deve ritrovare la stessa articolazione dellíapplicativo (successione di menù e maschere) affinché la navigazione risulti la più agevole possibile.
La terminologia utilizzata dallíutente deve essere presa in considerazione nella stesura del documento affinché sia ridotta al minimo la possibilità di ambiguità.
Per ambiguità si intende qui la possibilità che termini quali display, maschera , videata, oppure tasto, pulsante, o ancora cursore, mouse, puntatore ecc. , possano ingenerare confusione nellíutente.
I paragrafi salienti del Manuale dovrebbero essere posti in particolare risalto tramite adeguata simbologia ed i rimandi dovrebbero essere ridotti ai casi di effettiva necessità. Un indice per argomento dovrebbe corredare il testo per consentirne un agevole rintracciamento.
In Figura 6.4.2 si riporta il percorso metodologico di riferimento per la fase di Implementazione
Ogni Responsabilità viene implementata a partire dal Documento di Progetto e dal DFD, forniti rispettivamente a livello di Sottosistema 1 e Sottosistema i-esimo, producendo il Codice.
Il momento successivo è líintegrazione del codice di tutte le Responsabilità a livello di Sottosistema 1 per effettuare il test.
In caso di esito positivo il codice viene rilasciato a livello di Sistema.
I ritorni ai livelli precedenti avvengono solo quando si riscontrano delle anomalie nella fase di integrazione delle responsabilità a livello di Sottosistema 1 o di test del codice.
La produzione del Manuale Utente avviene a livello di Sottosistema 1 parallelamente alla produzione e test del codice, e viene anchíesso rilasciato a livello di Sistema.
Le fonti cui attinge sono il DFD ed il documento di Analisi.
Separatamente viene realizzata, a partire dallo Schema Logico, la Base di Dati a livello di Sottosistema i-esimo per tenere conto di eventuali frammentazioni e distribuzione.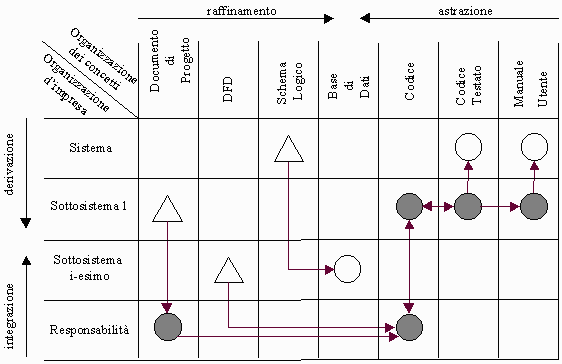
Figura 6.4.2 ñ Il percorso metodologico per la fase di Implementazione.