per individuare parti di un documento XML - specifiche W3C
in breve
È una sintassi per creare espressioni (pattern) che individuano i nodi di un albero XML. Assomiglia al path del File System. Gli attributi si estraggono con @.
Esistono numerose funzioni: count(), concat(,,,), substring(), string-length(), starts-with(), end-width(), number(), round(), floor(), ceiling() Ecco alcuni esempi:
/articolo/paragrafo/@titolo
/articolo/paragrafo[position()=2]
/articolo/paragrafo[position()=last()]
/articolo//immagine individua tutti gli elementi contenuti in qualsiasi livello.
È una sintassi per creare espressioni (pattern) che individuano i nodi di un albero XML. Assomiglia al path del File System. Gli attributi si estraggono con @.
- item seleziona tutti gli elementi denominati item
- parent/child seleziona tutti gli elementi denominati child il cui padre si chiama parent
- / seleziona la radice dell'albero
- text() seleziona nodi di tipo testo
- @att seleziona l'attributo di nome att
- item[@name='foo'] seleziona gli elementi denominati item che hanno un attributo chiamato name, il cui valore � foo
- @* seleziona qualsiasi attributo
Esistono numerose funzioni: count(), concat(,,,), substring(), string-length(), starts-with(), end-width(), number(), round(), floor(), ceiling() Ecco alcuni esempi:
/articolo/paragrafo/@titolo
/articolo/paragrafo[position()=2]
/articolo/paragrafo[position()=last()]
/articolo//immagine individua tutti gli elementi contenuti in qualsiasi livello.
1
XPath vede il documento XML strtutturato ad albero:
ogni elemento � un nodo, perci�:
XPath vede il documento XML strtutturato ad albero:
ogni elemento � un nodo, perci�:
- un elemento annidato � un nodo figlio dell�elemento che lo contiene
- un attributo � figlio del suo elemento
- processing instruction, testo e commenti sono figli dell�elemento che li contiene.
2
XPath opera su insiemi di nodi in relazione col nodo corrente (o contesto), detti assi.
L�asse default � l'asse degli elementi figli diretti.
Ci sono tag predefiniti: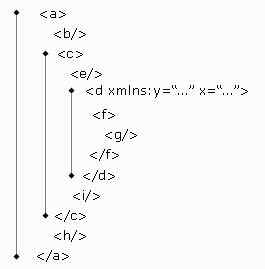
XPath opera su insiemi di nodi in relazione col nodo corrente (o contesto), detti assi.
L�asse default � l'asse degli elementi figli diretti.
Ci sono tag predefiniti:
- self: nodo corrente (d) - abbreviato con .
- attribute: del nodo corrente (x) - abbreviato con @
- child: elementi annidati nel nodo corrente (f)
- parent: nodo padre del nodo corrente (c)
- ancestor: tutti i nodi padre precedenti (c, a)
- preceding: tutti i nodi precedenti, tranne gli ancestor (b,e)
- descendant: tutti gli elementi annidati (f, g) - abbreviati con /
- following: tutti i nodi successivi, tranne i descendant (i, h)
- following-sibling: nodi 'fratelli' (i)
- namespace (y)
3
Per identificare un nodo, si usano test sul nome e/o sul tipo. I tipi sono:
Per identificare un nodo, si usano test sul nome e/o sul tipo. I tipi sono:
- elemento
- attributo
- namespace
- commento
- processing-instruction
I test restituiscono l�insieme dei nodi con quel particolare tipo presenti sull�asse.
Il test speciale * seleziona tutti i nodi dell�asse.
Il tipo predefinito per un asse �, nell'ordine, elemento, attributo, namespace.
Se esistono pi� nodi, le operazioni vengono applicate iterativamente a ciascun nodo, perci� il risultato � un insieme di nodi, ciascuno dei quali pu� essere ulteriormente attraversato usando XPath.
4
Una espressione XPath consiste in una serie di step costituiti da test separati da /
Ogni passo agisce sull�insieme di nodi (contesto) prodotto dal passo precedente.
Il primo passo ha un contesto fornito dall�ambiente.
Se il path inizia con uno slash il contesto � la radice.
Una espressione XPath consiste in una serie di step costituiti da test separati da /
Ogni passo agisce sull�insieme di nodi (contesto) prodotto dal passo precedente.
Il primo passo ha un contesto fornito dall�ambiente.
Se il path inizia con uno slash il contesto � la radice.
5
In ciascun passo, dopo il test, si possono inserire filtri racchiusi da [].
In ciascun passo, dopo il test, si possono inserire filtri racchiusi da [].
- se il risultato � 'true', il nodo viene aggiunto
- se il risultato � un numero, viene inserito il nodo nella posizione indicata
- se il risultato � un insieme non vuoto di nodi, equivale a 'true'
- espressioni XPath
- costanti numeriche
- stringhe (tra '')
- = != > >= < <=
- or and not
- + - * / mod
- | (unione)
- sugli insiemi di nodi: count(...) last() position() document(...) id(���)
- sulle stringhe: string(object) string-length(s) concat(s1,s2,...) substring(s,n,[l]) substring-after(s,t) substring-before(s,t) contains(s,t) starts-with(s,t)
- sui valori booleani: boolean(object) not(e) true() false()
- sui valori numerici: number(object) ceiling(x) floor(x) round(x) sum(ns)
- infine: current() per accedere al contesto XSLT